
서로소 집합(Disjoint Sets)
서로소 집합(Disjoint Sets)은 공통 원소가 없는 두 집합을 의미한다. 예를 들면 {1, 2}와 {3, 4} 가 서로소 집합에 해당된다.
서로소 집합 자료구조란 서로소 부분 집합들로 나누어진 원소들의 데이터를 처리하기 위한 자료구조라고 할 수 있다. 서로소 집합 자료구조는 union 과 find 이 2개의 연산으로 조작할 수 있다.
- union(합집합) 연산
- 2개의 원소가 포함된 집합을 하나의 집합으로 합치는 연산
- find(찾기) 연산
- 특정한 원소가 속한 집합이 어떤 집합인지 알려주는 연산
서로소 집합 자료구조는 합집합과 찾기 연산으로 이루어져 있다. 따라서 union-find 자료구조라고도 한다.
서로소 집합 자료구조
서로소 집합 자료구조를 구현할 때는 트리 자료구조를 사용하여 집합을 표현한다.
동작 과정
- union 연산을 확인하여, 서로 연결된 두 노드 A, B 를 확인한다.
- A 와 B 의 루트 노드를 각각 찾는다.
- A 를 B 의 부모 노드로 설정한다. (B 가 A 를 가리키도록 설정)
- 실제로 구현할 때는 A 와 B 의 루트 노드 중
더 번호가 작은 원소가 부모 노드가 되도록 구현하는 경우가 많다.
- 실제로 구현할 때는 A 와 B 의 루트 노드 중
- 모든 union 연산을 처리할 때 까지 1번 과정을 반복한다.
구현
예를 들어 {1, 2, 3, 4, 5, 6} 로 이루어진 집합이 있고, {1, 4}, {2, 3}, {2, 4}, {5, 6} 의 union 연산이 주어지면 다음과 같은 그래프 형태로 표현할 수 있다.
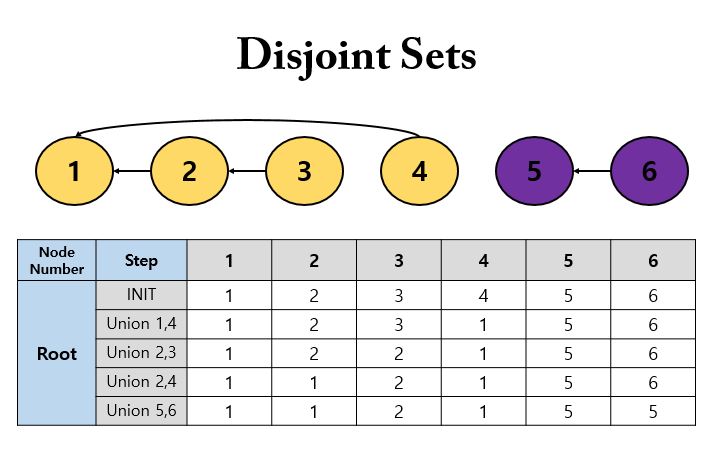
여기서 {2, 4} 에 대한 union 연산을 사용할때를 주의깊게 봐야하는데, 현재 4의 부모 노드는 1이고, 노드 2의 부모 노드는 2이다. 따라서 더 값이 작은 1을 root 노드 2의 부모로 설정한다. 이렇게 union 연산을 다 수행하고 나면, 노란색 노드랑 보라색 노드로 구분 지을 수 있다.
특징
특징은 union 연산을 계산하기 위해서 부모 노드 테이블(parents)을 가지고 있어야 한다. 루트 노드를 계산 하기 위해선 간선을 타고 올라가야 한다. 예를 들어, 3의 최종 루트 노드인 1을 찾기 위해서 2를 거쳐서 1로 가야 한다.
즉, 서로소 집합 알고리즘에서 루트 노드를 찾기 위해서는 재귀(Recursion)를 사용하여 간선을 타고 거슬러 올라가야 한다.
최종 구현 코드는 다음과 같다.
public class Main {
private static int vertexCount; // 정점, 노드의 개수
private static int edgeCount; // 간선의 개수
private static int[] parents; // 부모 테이블
private static final int[][] unionSets = new int[][]{ {1, 4}, {2, 3}, {2, 4}, {5, 6} }; // union 연산 대상 집합
public static void main(String[] args) {
input();
initParents();
unionOperation();
output();
}
private static void input() {
Scanner sc = new Scanner(System.in);
vertexCount = sc.nextInt();
edgeCount = sc.nextInt();
}
// INIT : 부모 테이블 초기화 -> 초기 root 노드들을 자기 자신으로 설정
private static void initParents() {
parents = new int[vertexCount + 1];
for (int i = 1; i <= vertexCount; i++) {
parents[i] = i;
}
}
// union 연산
private static void unionOperation() {
for (int i = 0; i < unionSets.length; i++) {
int firstVertex = unionSets[i][0];
int secondVertex = unionSets[i][1];
int firstParentVertex = findParent(firstVertex);
int secondParentVertex = findParent(secondVertex);
if(firstParentVertex < secondParentVertex) {
parents[secondParentVertex] = firstParentVertex;
} else {
parents[firstParentVertex] = secondParentVertex;
}
}
}
// find 연산
// 특정 원소가 속한 집합을 찾기
// 루트 노드 조건 : vertex == parents[vertex] (파라미터로 보낸 노드의 값과 부모 테이블에 저장된 값이 일치)
private static int findParent(int vertex) {
// 루트 노드가 아니라면, 루트 노드를 찾을 때까지 재귀적으로 호출
if (vertex == parents[vertex]) return vertex;
return findParent(parents[vertex]);
}
private static void output() {
// 각 원소가 속한 집합 출력하기
System.out.println();
System.out.print("각 원소가 속한 집합: ");
for (int i = 1; i <= vertexCount; i++) {
System.out.print(findParent(i) + " ");
}
System.out.println();
// 부모 테이블 내용 출력하기
System.out.print("부모 테이블: ");
for (int i = 1; i <= vertexCount; i++) {
System.out.print(parents[i] + " ");
}
System.out.println();
}
}소스를 분석하면 다음과 같다.
vertexCount: 입력 데이터 n(Ex. 반 학생 N 명)edgeCount: 숫자쌍 M 개(Ex. {1, 2}, {2, 3} ...) 즉, unionSets 를 의미하면서 간선의 개수를 의미parents 배열: 인덱스 번호는 정점을 의미. 따라서, 자기 자신 정점에 대한 부모를 가지고 있는 리스트init parents: 초기 부모(root) 노드를 다 자기 자신으로 설정union: union 연산 수행. 간선의 개수(edgeCount) 만큼만 수행된다.find: find 연산 수행. 자신의 최상위에 있는 부모를 찾으려면 거슬러 올라가야 하므로 union 연산 내부에서 find 연산으로 자신의 부모를 찾고 값일 비교하여 parents 리스트를 갱신
만약에 문제에서 union-find 연산을 다 수행하고나서 마지막 줄에 입력 값으로 두 원소가 연결되어 있는지 확인하는 숫자 쌍 Ex. {3, 8} 이 주어진다면 출력문에서 find 연산을 수행해야 한다.
private static void output(int x, int y) {
int parentX = findParent(x);
int parentY = findParent(y);
if (parentX == parentY) {
System.out.println("YES");
} else {
System.out.println("NO");
}
}위 코드의 단점은 부모 노드를 찾기 위해서 거슬러 올라가야한다는 점인데, 노드의 개수가 V 이고 find or union 연산의 개수가 M 일때 시간복잡도는 다음과 같다.
$$O(VM)$$
시간 복잡도를 개선하기 위해선 경로 압축(Path Compression) 기법을 적용하면 된다.
경로 압축(Path Compression)
// 경로 압축 기법 적용
private static int findParentBypathCompression(int vertex) {
if (vertex == parents[vertex]) return vertex;
return parents[vertex] = findParent(parents[vertex]);
}경로 압축은 재귀를 호출한 결과를 부모 테이블에 갱신해주는 것이다. 시간 복잡도를 줄이는 방법은 경로 압축외에도 많다고 한다. 경로 압축을 적용한 시간 복잡도는 다음과 같다.
$$O(V + M(1 + log_{2-M/V} V))$$
서로소 집합을 활용한 사이클 판별

- 동작 방식
- 초기 단계에서 자기 자신을 부모로 초기화하고, 각 단계마다 더 작은 값을 갖는 노드를 부모 노드로 변경한다.
- 모든 간선을 하나씩 확인하여, 매 간선 마다 union, find 함수를 호출하는 방식
- 무 방향성 그래프에서만 적용 가능
구현
public class Main {
private static int vertexCount; // 정점, 노드의 개수
private static int edgeCount; // 간선의 개수
private static int[] parents; // 부모 테이블
private static final int[][] unionSets = new int[][]{ {1, 2}, {1, 3}, {2, 3} }; // union 연산 대상 집합
private static boolean cycle = false; // 싸이클 발생 여부
public static void main(String[] args) {
input();
initParents();
if(isOccurCycling()) {
System.out.println("Occur Cycling");
} else {
System.out.println("Not Occur Cycling");
}
}
private static void input() {
Scanner sc = new Scanner(System.in);
vertexCount = sc.nextInt();
edgeCount = sc.nextInt();
}
// INIT : 부모 테이블 초기화 -> 초기 root 노드들을 자기 자신으로 설정
private static void initParents() {
parents = new int[vertexCount + 1];
for (int i = 1; i <= vertexCount; i++) {
parents[i] = i;
}
}
// 싸이클이 발생했는지 판단
private static boolean isOccurCycling() {
for(int i=0; i<unionSets.length; i++) {
int firstVertex = unionSets[i][0];
int secondVertex = unionSets[i][1];
// 싸이클 발생 시 종료
if(findParent(firstVertex) == findParent(secondVertex)) {
cycle = true;
break;
} else { // 싸이클이 발생하지 않으면 union 연산 수행
unionParent(firstVertex, secondVertex);
}
}
return cycle;
}
// find 연산
private static int findParent(int vertex) {
if (vertex == parents[vertex]) {
return vertex;
}
return parents[vertex] = findParent(parents[vertex]);
}
// union 연산
private static void unionParent(int firstVertex, int secondVertex) {
int firstParentVertex = findParent(firstVertex);
int secondParentVertex = findParent(secondVertex);
if (firstParentVertex < secondParentVertex) {
parents[secondParentVertex] = firstParentVertex;
} else {
parents[firstParentVertex] = secondParentVertex;
}
}
}References
'Algorithms > 기본 지식' 카테고리의 다른 글
| 위상 정렬 (0) | 2021.12.14 |
|---|---|
| 신장 트리와 크루스칼 알고리즘 (0) | 2021.12.13 |
| 플로이드 워셜 알고리즘 (0) | 2021.12.12 |
| 최단 경로와 다익스트라 알고리즘 (0) | 2021.12.11 |
| 다이나믹 프로그래밍 (0) | 2021.12.11 |